The future of combining marks.

James Puckett
Posts: 2,051
How far away is a future in which precomposed characters built of letters and diacritical marks are no longer in fonts because they’re all composed on the fly with mark-to-base and mark-to-mark? Will we soon hit a point at which users can enter arbitrary mark combinations without having to input the combining versions marks which are not accessible from most keyboard layouts? It seems like browser developers are moving in this direction, but what about the rest of the software and OS world?
0
Comments
-
The latest version of Pages, Numbers, and Keynote support it. That probably means Mac OS X 10.11 does, too.0
-
How far away is a future in which precomposed characters built of letters and diacritical marks are no longer in fonts...
This came up at the OTL implementation meeting last week. Kamal Mansour from Monotype refloated a concept that he and I had first proposed to the OT mailing list a few years ago: a new cmap subtable format that would map from individual Unicodes to multiple glyph indices. This would enable bypassing the need for precomposed diacritic characters.
Unfortunately, the decision at the meeting was that this would involve significant problems for software makers, far outweighing the benefits considering that alternative methods exist to handle decomposition at the glyph processing level and automation of precomposed diacritics at the font tool level. Apart from needing to update software to recognise the new cmap format (during which time the precomposed diacritics would need to be included for backwards compatibility, likely for several years), there are performance implications for calculating buffer sizes when the ratio of glyph IDs to characters becomes essentially arbitrary.
So even though dynamic GPOS mark positioning is widely supported, and keyboard input for combining marks can be improved, there won't be a method to completely bypass precomposed diacritic characters at the font level.
There are some other options:
a) At the font level, developers could follow Adam Twardoch and Karsten Luecke's webfont approach, and simply use empty glyphs for the precomposed diacritic characters and decompose these to appropriate bases and combining marks in the 'ccmp' feature. This, unlike the cmap approach, doesn't save you GIDs, but unless you're making maxed-out CJK fonts à la Source Han Sans that's not a practical issue. Note, however, that a bug in InDesign fails to apply the 'ccmp' feature to decompose all precomposed diacritics.
b) At the text engine level, software could be changed to apply Unicode normalisation form D (decomposed) before applying OTL, performing a buffered conversion of precomposed characters to canonical decompositions. This is, in effect, the opposite of what many layout engines already do, mapping decomposed sequences to precomposed diacritics if available in the cmap table. Of course, knowing which mechanism to apply depends on knowing how the individual font is made. I'm considering proposing a new flag to be able to indicate that a given font either does not contain precomposed diacritics or prefers decomposed layout to be applied (that enables a single font to both opt for the new mechanism while providing backwards compatibility).1 -
Applying Unicode normalisation doesn’t handle the case of wanting to decompose glyphs for characters that have no Unicode decompositions (like Arabic letter which Unicode doesn’t, and as a policy will not, provide decompositions for). Since special cmap table was ruled out, I’m not sure what a mechanism can handle both cases.
Another approach is to use “ghost” glyph ids instead of empty glyphs, i.e. the cmap will point to glyph ids with no corresponding entries in glyf and similar tables, and ccmp would map them to the actual decomposed glyphs. This should theoretically work, but I couldn’t convince any font generation tool to let me do this so can’t verify if it actually works (IIRC, Graphite uses this concept extensively, but that is a different beast and they control the only implementation).
0 -
Mapping to unencoded glyphs has to fall back to 'ccmp', which is reasonable enough for a glyph processing operation, although I would have liked the cmap option.
The ghost GID idea is interesting, but I'm not surprised you've had trouble trying to build such a font.
_____
Behdad reports that Harfbuzz is already doing 'magic' normalisation during layout:If your font supports any sequence that is canonically equivalent to the input sequence, we use it. This is where the magic happens:
So that opens the door to the kind of font that James and others want to make, without precomposed diacritic glyphs. Of course, this only works for characters with Unicode canonical decompositions; additional decompositions will still need to happen in 'ccmp'.
https://github.com/behdad/harfbuzz/blob/master/src/hb-ot-shape-normalize.cc#L320 -
But what if you want alternate accents for a character, say lower case /i — with a dieresis having the dots closer together and the macron narrower?0
-
But what if you want alternate accents for a character, say lower case /i — with a dieresis having the dots closer together and the macron narrower?
Wouldn’t CALT work for that?
0 -
I'd be inclined to put that kind of contextual substitution into the 'ccmp' feature, to ensure that it is active from the outset. Although technically not a composition or decomposition substitution, it is related to how you intend decomposed sequences to be displayed.0
-
Similarly, in Arabic I do my decompositions in init, medi, etc features not in ccmp because not all characters have the same number of dots or the same placement in all positions in word.
0 -
Well this is often made by `ccmp`, like this:James Puckett said:But what if you want alternate accents for a character, say lower case /i — with a dieresis having the dots closer together and the macron narrower?
Wouldn’t CALT work for that?
sub [i cyrUkraniani j cyrje iogonekBelow]' @AboveMarks by [dotlessi dotlessi dotlessj dotlessj iogonek.dotless];
0 -
Regarding the ghost GIDs: I assume Graphite folks took the idea from Apple, as they have no problem with arbitrary glyph IDs either. In the tutorial for their font tool suite, Apple explicitly talks about non-existent GIDs in case some feature requires you to use several shaping passes, during which particular glyph might get ‘lost’, thus needs to be marked somehow. It’s also a way to temporarily exempt some glyph from potential substitutions in passes that follow. You just have to make sure to switch to a real glyph before the line gets rendered, otherwise bad things will happen.0
-
My general approach is to provide precomposed glyphs if the marks overlap with the base outline in any way. In some cases, this results in using composites or merging outlines in a way that does not require any subsequent design work, i.e. the precomposed are identical to the results that could have been achieved using mark positioning. This is fairly frequently the case, for instance, for the letters with cedilla. More complex intersections of marks and bases, frequently benefit from weight and shape adjustments, especially in heavier cuts. I've chosen to always handle these as precomposed glyphs so as not to have to manage too many variances in glyph sets, and so I am ready if, for example, a client requests a black extension to a family in which mark positioning would be impractical for these diacritics.
Unicode recognised the impracticalities of handling things like overlaid bars and slashes as combining marks, and would encode such diacritics as precomposed characters without canonical decompositions to the existing overlay marks (Unicode has commitments that prevent it from encoding any more characters with canonical decompositions).Connection points & slant angle is really all one needs in the font file – the engine could take care of the rest.
Not sure what you mean by 'connection points' or how this differs from the current situation.1 -
But what if you want alternate accents for a character, say lower case /i — with a dieresis having the dots closer together and the macron narrower?
Actually I stumbled over this topic by coincidence a few days ago. I also read the related info on the Glyphs website and this made me wonder how to circumvent that all base characters are combined with all diacritics, i.e., how to create specific combinations such as for the lowercase /i with an adapted diacritic, as mentioned by Nick. My colleague Hartmut Schwartz at URW++, who is one of the programmers of OTM, pointed me to using lookups. So, I puzzled a bit earlier today and the example below seems to work. BTW, I’m doing the horizontal fine tuning of the diacritics in OTM’s GSUB/GPOS Viewer.
# --- Supports OTF Standard West code page (more or less)
# --- Uses GPOS mark-to-base for characters with diacritics
# --- FEB, 18 February 2016
# --- LANGUAGESYSTEMS
languagesystem DFLT dflt;
languagesystem latn dflt;
lookup MRKCLS_1 {
lookupflag 0;
markClass [gravecomb acutecomb circumflexcomb dieresiscomb tildecomb caroncomb] <anchor 0 0> @DIACRITIC_TOP_1;
pos base [a c e o s u z] <anchor 0 0> mark @DIACRITIC_TOP_1;
} MRKCLS_1;
lookup MRKCLS_2 {
lookupflag 0;
markClass [cedillacomb ogonekcomb] <anchor 0 0> @DIACRITIC_BELOW;
pos base [a c] <anchor 0 0> mark @DIACRITIC_BELOW;
} MRKCLS_2;
lookup MRKCLS_3 {
lookupflag 0;
markClass [dieresiscomb.i] <anchor 0 0> @DIACRITIC_TOP_2;
pos base [dotlessi] <anchor 0 0> mark @DIACRITIC_TOP_2;
} MRKCLS_3;
feature ccmp {
# --- Glyph Composition/Decomposition
sub i' @DIACRITIC_TOP_2 by dotlessi;
sub j' @DIACRITIC_TOP_2 by dotlessj;
} ccmp;
feature mark {
# --- Mark to Base positioning
lookup MRKCLS_1;
lookup MRKCLS_2;
lookup MRKCLS_3;
} mark;
@BASE = [a c e o s u z dotlessi];
@MARKS = [@DIACRITIC_TOP_1 @DIACRITIC_TOP_2 @DIACRITIC_BELOW];
table GDEF {
GlyphClassDef @BASE,,@MARKS,;
} GDEF;
1 -
For me one of the most interesting aspects of applying mark-to-base for Latin is that this allows the contextual offset of diacritics. The images below show the substitution of the precomposed edieresis with the mark-to-base variant, and subsequently I made a contextual variant in which I moved the dieresis on top of the lowercase e away a bit from the top of the T and the terminal of the f. I didn’t look much at the positioning itself; I’ve just been testing the system. I’ve used OTM 6 (which will be released first of March) for checking the syntax, compiling the features, and testing the outcome.

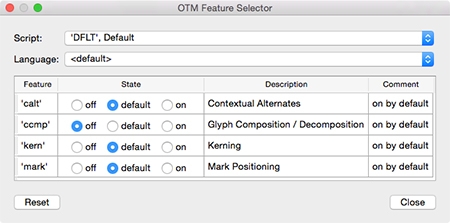
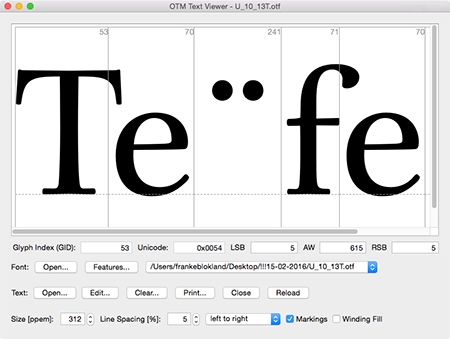
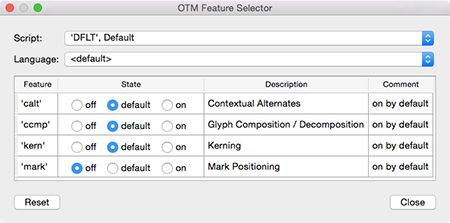
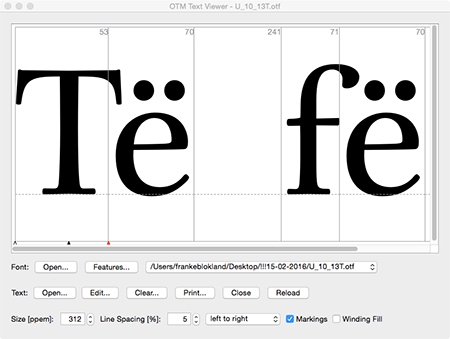

Of course, in case of the f one can also use a variant with a shortened terminal to prevent problems with the dieresis. If one looks at Jenson’s ‘Eusebius’ type, then it seems that Jenson also did offset diacritics (I didn't find shortened terminals of the f and long s in his roman type).
4 -
Jenson’s most famous offset diacritic: the flying tittle.0
-
It’s a bird… it’s a plane… it’s the flying tittle!
0 -
The idea is attractive, but Jenson's tilde was not exactly a diacritic mark and its position was not offset to avoid collisions.
In Medieval Latin, early tilde was an abbreviation mark to -am and -um endings, developed to save space in papyrus and parchments. Tilde was later used to sign long nasalization of a vowel even inside a word. Its position centered over the vowel was not well established until late 17th Century, being used before mostly as Jenson did.
Portuguese vowel combinations like ão appear as ão, aõ and with a tilde over both vowels in books up to 1800.
Some samples:
1578: published in France, with no city indication. Text in French.
1659: published in Lisbon. Text in Portuguese.
1747: published in Rio de Janeiro, very first book printed in Brazil. Text in Portuguese.0 -
The idea is attractive, but Jenson's tilde was not exactly a diacritic mark and its position was not offset to avoid collisions.
Well, I tend to disagree with you on this.Its position centered over the vowel was not well established until late 17th Century, being used before mostly as Jenson did.
Really?
Sweynheym and Pannartz’s type as used in Opera from 1469 (Museum Meermanno col.):
Da Spira’s type as used in Historia Alexandri Magni from 1473 (Museum Meermanno col.):
Griffo’s type as applied in Hypnerotomachia Poliphili from 1499 (Museum Meermanno col.):
2 -
Frank, thanks for the samples. They show I must remove "mostly" from my prior statement. But I still do not identify an evidence of Jenson's intention to avoid collisions. Griffo's sample even shows both tilde positions, reinforcing the lack of a clear standard.0
-
Currently, some important apps don’t run ccmp at all. Karsten & I wrote a tool that illustrates the blank-glyph approach, see:
https://github.com/twardoch/ttfdiet/
The Readme has some test results.2 -
-
Congratulations on OTM 6 Frank!1











Categories
- All Categories
- 47 Introductions
- 4K Typeface Design
- 493 Type Design Critiques
- 575 Type Design Software
- 1.1K Type Design Technique & Theory
- 669 Type Business
- 884 Font Technology
- 29 Punchcutting
- 537 Typography
- 124 Type Education
- 332 Type History
- 81 Type Resources
- 113 Lettering and Calligraphy
- 33 Lettering Critiques
- 80 Lettering Technique & Theory
- 569 Announcements
- 100 Events
- 116 Job Postings
- 170 Type Releases
- 182 Miscellaneous News
- 270 About TypeDrawers
- 54 TypeDrawers Announcements
- 114 Suggestions and Bug Reports