implemented raph levien's curve fitting algorithm for merge/simplify #4697
Conversation
|
Obviously before this is eventually accepted the How does the performance compare to the "old existing" algorithm? If it's good are you keeping I'm a bit surprised at all the trig. Is that just how the calculation you're working from was written or did you consider and reject replacing a bunch of that with unit vectors? |
|
I have thought that I have already removed the printf's - but obviously in a different version... After the last commit they should not appear anymore. I think there is no need for TRACE - it seems to be stable for merging/simplifying (but I just have tested it with 20 different fonts). The performance compared to "my" brute force algorithm is much better, I would guess about 1/100 as much loops as in the brute force for the generic case (but I think this doesn't make it exactly 100 times faster - but at least 10 times faster). The performance seems to be comparable to George Williams algorithm. That's why I used it for "simplify" as well. On my computer, the simplify action for a 1600 glyph font still feels instantaneous. Indeed, I keep For me, this patch is better than the brute force algorithm and George William's algorithm. But I think somebody of the FontForge team should test this patch and judge himself/herself if it's better for a majority of users. By the way: Please excuse the introduction of the snake_case for About trigonometry: I don't think that things will speed up if I replace |
Can you give me a reproducible test case for this?
We don't have an "official" code style but snake-case for variables is preferred, I think.
The question was more about why the code is doing anything with angles in the first place. I might be biased but I think of trig as a sort of cheat or work-around for when vectors aren't handy and it has a reputation for being a bit "expensive" computationally. Try this out for comparison: |
|
(I'm not going to stamp my foot and require a no-trig solution but is a roundabout way of negating a value ... ) |
The concern about this may not be just a matter of taste. Apparently this exposes a bug in the stroking algorithm, which we should fix (or at least prevent the crash). That demonstrates a general worry: adding such splines to contour geometries could trigger bugs in other downstream spline-processing algorithms. I don't think we should necessarily prohibit them but at a minimum I'd be inclined to avoid them in Element -> Simplify -> Simplify with a not-checked-by-default checkbox in "Simplify More" and an analogous flag in |
|
Well, the part was unnecessary, indeed. The rotation can be done directly using ftunit. I was not aware of Thanks for the hint About tunni-point-excess: I will make a further commit for it. |
…d the Tunni point
|
The algorithm now does no longer produce handles that exceed the Tunni point (see last commit). It seems to work fine and it may be wise to keep this behaviour anyway. But I was not successful changing all flags |
I added
I think this is fairly simple and needs fixing. If you look at (current) lines 744 through 758 you'll see that the The This seemed to do the trick with some basic testing: what do you think? |
|
I think it works! Thanks for the patch! Now that there are no segmentation faults anymore I have tested the speed: The new algorithm causes stroking to be about 8 times slower than before. I can probably fiddle the algorithm a bit more to be faster (the comparison of the L2-error is somewhat slow, I should take the parametrization time of the fitting points in account as well). This will need some time... |
|
At the time I felt like 1em accuracy could lead to some visible distortions. The thing about stroke expansion is that people are pretty good at judging consistent width vs changes in width, so I felt it was OK to be extra picky by default. |
|
I have tested several mechanisms to choose the approximation with the lowest error (those by George Williams as well). But it does not speed up much. And now I suppose that the old algorithm is indeed the better choice for the current stroking algorithm because it calls |

|
@linusromer There are basically four sources of points in the expand stroke system:
In short, there's nothing in the algorithm that generates co-located control points like those in your sample. I'm not sure how you generated that curve, and I'm happy to help you look into it, but my initial suspicion is that somewhere in your test code you've converted to a quadratic contour and back to a cubic contour -- that's the easiest way to wind up with contours of that form. |
|
On the more general question I believe any calls from the stroking algorithm to |
|
@skef You are right, I was wrong about the standard stroking algorithm. I was misled by the following effect (original S, stroked S using the standard |
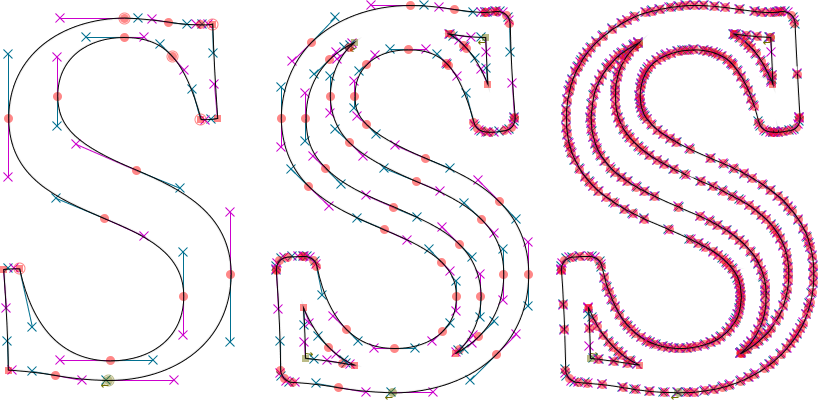
|
The simplify option to the stroking algorithm post-processes the contours separately by calling the regular Simplify facility (with particular options). This is to remove potentially "unnecessary" points of types 1 and 2 in my list above. (If the nib points or source contour points are smooth there's a good chance you won't need the corresponding points on the output contour. On the other hand if you're trying to make a variable font by stroking at different nib magnitudes you probably need all of those...) |
|
@linusromer I think this is good news, by the way. The place to look for this problem is in This is good news because there are so many more splines being fit than before, so once the problem is diagnosed I expect the performance will be comparable to the old fitting algorithm. |
|
On the error metrics: It seems like there must be a maximum "slop" between source t values and candidate t values that could probably be determined experimentally if not analytically. If there is then the |
…d only if the other solutions are not suitable
|
About the idea with the maximal "slop": The slop becomes maximal when one handle is 0 and the other is infinitely long. The maximal slop with "reasonable" handles seems to be about +/- 0.4 when comparing the time to the normed time (normed = parametrized by arc length and divided by the total length). Assuming the maximal slop +/- 0.5 seems to be safe. And guess what: I have measured the time and it practically does not matter. (Storing Anyway, I have compared the time with the error computation of And this was way slower! (About 40 times for maxerr, about 30 times for the summed up error). Concluding from these (and other experiments) I still favour my current error computation. So I have to check what goes wrong elsewhere with stroking and my implementation. |
|
Going back to the other problem does the version with If we eventually get this figured out we could expose an interface (probably with a passed struct or something) to retrieve the worst fitting point, and may be the distance, so that doesn't have to happen twice. That should make the overall system quite a bit faster. |
|
BTW that's not quite the right spline calculation -- With this very simple single spline: and a 50 em-unit circle nib at 0 degrees that diff prints: You can see the "divide and conquer" at the next level up here, with the splines getting shorter. The ~200 is the attempt at the outer offset of the whole spline and the ~146 is the attempt at the inner offset of the whole spline. The main thing I'm noticing here is that 32.6 em-units seems like a huge error for a relatively boring curve (represented with fit points) with 200 em-units between the endpoints. Same with 146 and 23.8. Looking at the individual distance values from that 200 em-unit fit: So what's it doing? I tried turning the accuracy down to 50 em-units to get the top-level splines and I see this:
After staring at this a bit I tried printing the distance between the control points and corresponding base points and got 1 and 0, which made me suspicious and I think I know roughly what the problem is. Your calculation of nextcp and prevcp is:
It seems like the algorithm is making more assumptions than that about the input control point positions but you're the right person to judge that. |
Yes, in my tests the version with SplineMinDistanceToPoint() has the too-many splines problem as well.
I actually already tested it before in the order that you suggest, but strangely the "to.prevcp" point is identical with the "to" point after either applying SplineMake() or SplineRefigure(). I have now again tested the following simple spline and got: As you can see, it is no surprise that the error is the same for every solution, because |
|
Oh, yeah, my code was only appropriate post- #4125 . Before that you have to manipulate nonextcp and noprevcp yourself (presumably by setting both to false before calling |
|
Anyway I think the thing to concentrate on here is |
|
I think I am beginning to understand now. My assumption that |
|
Okay, my assumption that The original code does some matrix magic and then gets: and I do some other magic and then instead where |
|
Ah, OK, I've read back through the article and your code and can now offer the primary suggestion to punt on using this for Expand Stroke and the secondary suggestion to perhaps rethink where you're adding this algorithm to the FontForge code. Discussing the second suggestion should start to clarify the first. The basic issue is that this algorithm isn't really fitting the passed points, it's just using the points as a measure of or check on the fit to the original splines. The easiest way to see this is just to look at the calculation of To use this method with the stroke code we'd either need to: a) come up with a parametric or other closed-form expression of the offset curve from which to calculate Accordingly the current algorithm isn't really fitting the points and therefore doesn't obviously belong integrated into If you wanted you could play around with a linear approximation of |
|
Just to clarify the scope of the Levien approach a bit: How does the system generate those stroke fit points? Well, the source curve being stroked takes the form of a cubic spline, so that part is easy. When you're stroking with a circular nib you can just calculate the normal from t and add the radius to it for the offset, and that can (probably?) given a closed form solution easily enough. When stroking with a polygonal nib you don't even fit points -- those are just spline segment offsets connected with lines. However, the FontForge system in particular doesn't actually stroke with a circular nib even when it claims to -- it strokes with a four-cubic-spline circle approximation (for reasons of generality). There are a lot of heuristics to determine when fitting should start and end so the problem boils down to stroking the source spline with the relevant spline on the nib. The fit points are calculated this way:
(This sort of makes it sound as if the "center" of the nib is assumed to be at 0,0 as that is kind of what treating a position as a vector amounts to. But it's more that the center of the nib per se is irrelevant -- the offset curve will just be displaced from the source curve by the distance between the nib and 0,0. If you don't want the curve offset centering the nib is your problem.) It's the transition from 3 to 4 that makes a closed form tricky. You would basically need to reparameterize the nib spline by tangent angle. That's guaranteed to be 1:1 because nibs are required to be convex, but if there's a straightforward equation mapping tangent angle to offset for a cubic spline I haven't found it yet. |
That would be very very hard if not impossible.
I agree. Maybe we should use Levien's algorithm exclusively for merging and simplifying (see my last commit)? |
|
There's a remaining wrinkle with this new change. The current stroking algorithm is much, much faster than the previous one but there's nothing dictating any given speed. I was planning to add a knob that lets it use your more accurate fitting algorithm for users who want to reduce the number of fit-generated points. Unfortunately that algorithm is gone now, which is a shame given the more narrow scope of the new one. Could we get it back, and maybe use an enum (or whatever) to choose between the options? |
|
Adding the mid-old brute force algorithm as a third alternative is surely no problem. But I think it is not necessary, because simplify can be applied after stroking. Wouldn't it be better if your "knob" refers to the exactness of the simplify function? |
|
There's already an accuracy parameter that feeds into both the fitting algorithm and the simplify post-processing (if that's turned on). I guess that's one way to go. There are some subtle potential advantages to doing it the other way but they can be duplicated with some work. |
…-old bruteforce algorithm
|
Taking
At the moment, |
|
Please wait for the merge of this patch. I have discovered a "merge-to-single-cyclic-segment"-issue with the new algorithm that was not around with the old algorithm: |
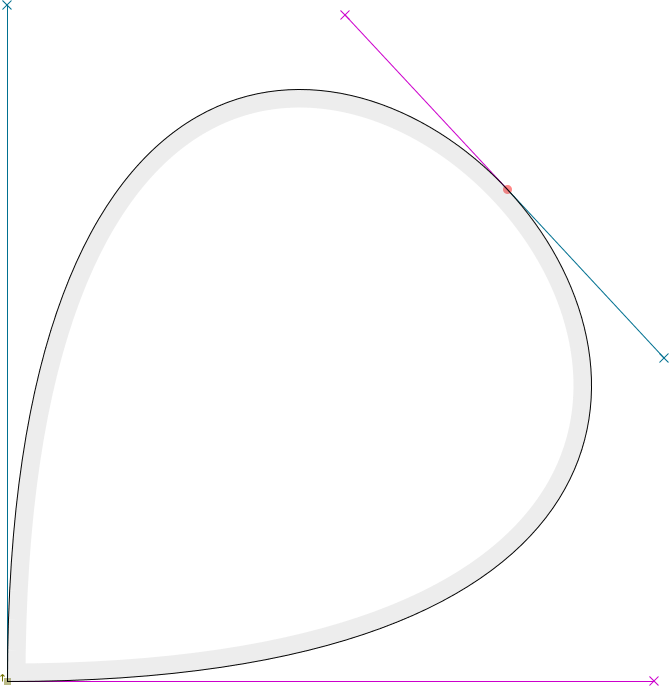
…which is not the same)
…he original algorithm in this case
|
With the last commit, the "merge-to-single-cyclic-segment"-issue is solved. |
|
I once had tested the original |
|
Sorry -- I'll try to get back to reviewing this shortly. |
|
I lied (obviously). I got pulled into some work-work. There's another spate of reviewing on the near horizon and I'll help out with that as I can. I fully expect this to be merged before the next release of FontForge. |
…ic equation reduces to a quadratic equation
Implementation of Raph Levien's curve fitting algorithm for merge/simplify
Raph Levien has published a curve fitting algorithm (called "merge" in fontforge) on his blog. I have discussed the algorithm with Raph and others on typedrawers. I have calculated the relevant parts (like the quartic equation of the moment-error) and implemented it for FontForge in splinefit.c. There is one small change that I added in comparison to Raph's original proposal: Near zeroes of the other handle length are considered as well.
This pull request is a kind of follow-up to this issue.
This algorithm seems to be superior to old the one I have used in this pull request here. The old algorithm was brute force and therefore limited in its exactness - and it was slow.
This algorithm is much faster and therefore may be used for simplifying too.